Undirect
Completely serverless URL shortening
In the realm of URL shortening and redirection, the term "serverless" is often thrown around. However, upon closer inspection, one usually finds that a server of some sort, like AWS Lambdas, is involved in the process.
My curiosity led me on a journey to discover if it's plausible to create a URL shortening service devoid of servers—essentially, without deploying any computers running my code, at least for the actual redirection process. I will delve into this in detail as we proceed.
This exposition won't follow a step-by-step tutorial format, but will rather share the fundamental concept and my thought process, accompanied by occasional snippets of code to elucidate key points.
Selecting a Hosting Provider #
For this venture, I chose AWS, as it's a platform I am quite familiar with, having utilized it for a myriad of projects, both large and small.
In a previous project named Undicat, AWS' Api Gateway was instrumental in processing millions of requests per second with relative ease, making it an appealing starting point for this endeavor.
I opted for Serverless as the template engine, appreciating its straightforward YAML syntax, and also because I intended to incorporate the shortener into an existing project.
Formulating the Basic Logic #
With the hosting and configurations settled, it was time to deliberate on how to structure the actual logic.
The requirement was to have two distinct endpoints: one for creating URLs and generating a unique URL, and another for managing the redirects.
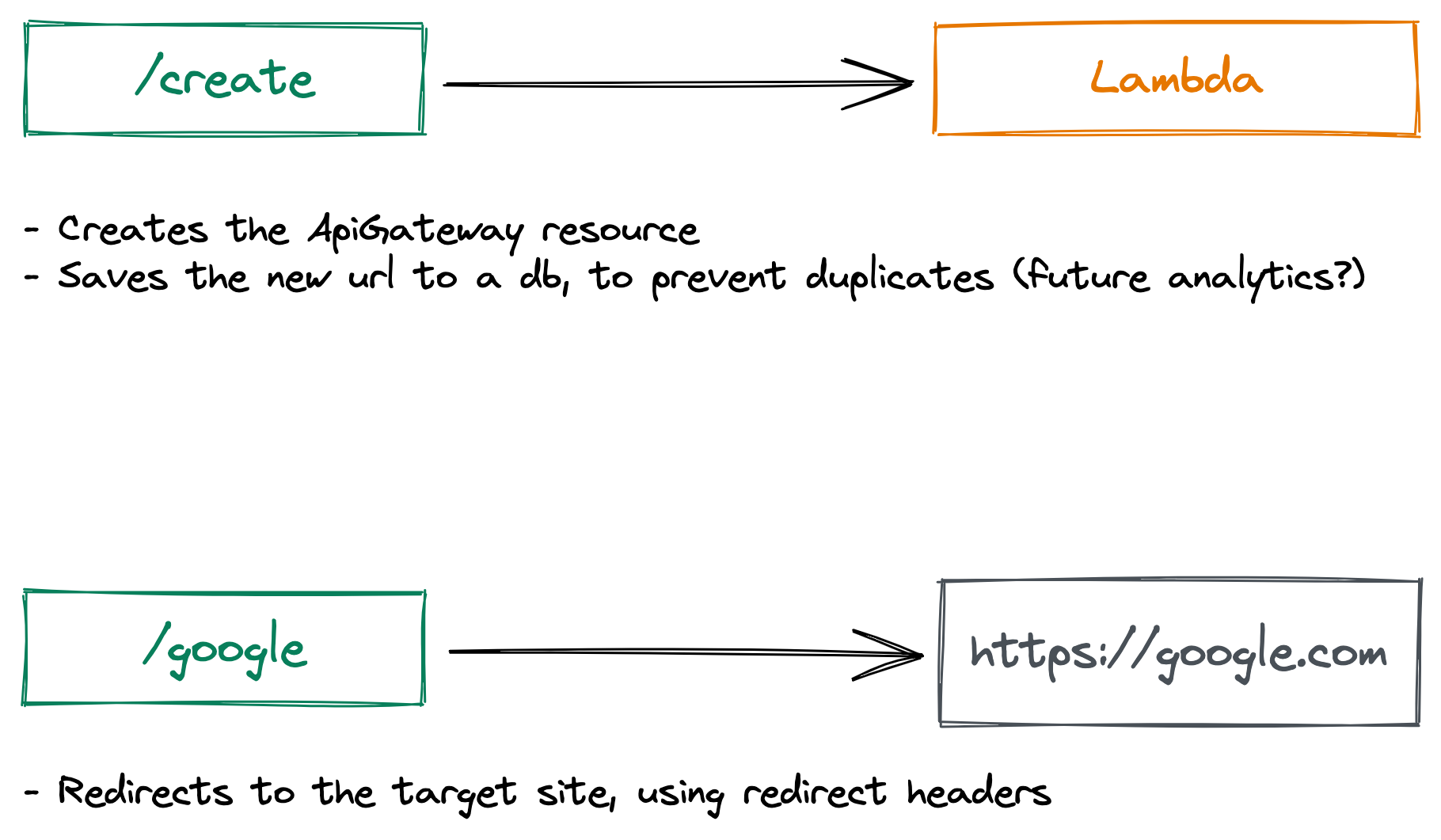 All the endpoints needed for the whole logic
All the endpoints needed for the whole logic
Setting up the first endpoint was straightforward. I established a new ApiGateway endpoint, attaching a Lambda Proxy to it. (Yes, for this part, I employed a lambda function—this is the sole portion of the application that engages any servers.)
At this juncture, the function receives a URL and an optional key as inputs, generates a random nanoid, and diligently stores everything in a Postgres database—simple as that.
Managing Redirects #
With the initial step completed, the focus shifted to devising a method to manage the redirects.
My initial thought was to create a resource and a method for each URL, employing a simple mock HTTP response for them. However, I quickly discerned that this approach would falter unless the user inputs the correct URL, as it would not adhere to any redirects. Manually entering headers and response codes seemed excessive, and even after such setup, the redirected URL would fail to follow if it had been moved or redirected elsewhere.
It was at this point that I began exploring custom integration responses. Leveraging some prior knowledge, I swiftly crafted a basic integration request and response.
1Copy code2#set($context.responseOverride.header.location = 'https://szalay.me')##3#set($context.responseOverride.status = 307)##4{}Here, I instructed the request to consistently return a 307 status code and include the location header, with the previously set URL. This configuration operated flawlessly—upon opening the random URL, Api Gateway autonomously utilized the correct resource and redirected the user to the specified page.
However, a limitation surfaced: Api Gateway inherently supports only 300 resources per Gateway. While a limit increase request was an option, it wasn't a scalable solution.
A workaround emerged—incorporating a JSON in the response integration and selecting the appropriate URL from the list, which could be hosted on AWS S3. Yet, a minor snag remained due to the modest memory limit of the integration response—512kb at the time of penning down this narrative. This constraint limited the method to a maximum of 4000 entries, as per my experimentation.
Nevertheless, a solution presented itself—allowing the URL to pass through and be managed by another resource. Since Api Gateway permits multiple catch-all routes under a single path, a new resource could be created whenever the 4000-entry-threshold is met. Theoretically, with the default 300 resource limit, this setup could accommodate approximately 2 million entries.
At this juncture, I decided to pause, deeming this capacity adequate for a preliminary experimental project, though I am optimistic that options exist to extend this limit further.
Embarking on an Adventurous Journey #
I initiated this project with scant knowledge on how the node.js AWS SDK handled ApiGateway updates, and soon discovered it to be a challenging endeavor.
The API permits only minimal updates per request, with the creation logic consuming over 150 lines of code, constituting 97% of the entire codebase, solely for creating and updating ApiGateway resources.
Achieving a Truly Serverless URL Shortener #
And so, after three hours of development, the outcome was a genuinely serverless URL shortener application.
Having utilized it extensively, I deduced the following:
Speed? Absolutely, with a mere 40 ms required to process each request—a remarkable feat compared to lambda! Elegance? Unfortunately not, as I employed solutions I hesitate to disclose. Scalability? A resounding no—the current performance indicates that handling requests in the last resource would consume 800ms. Despite these findings, the application adeptly fulfills its purpose—managing URL shortening for undicat.com, like https://undi.cat/orm.
A notable advantage of employing ApiGateway is the feasibility of implementing URL analytics virtually free of charge, without the necessity of engaging any lambdas for the redirects. I plan to elaborate on this in an upcoming article.
I trust you found this narrative enlightening, shedding light on an amusing albeit inconsequential project.
Should you harbor any inquiries or suggestions, feel free to engage me on Twitter.
Until then, I wish you a productive and pleasant day! ✌️